
在前面的三篇文章中,我们一起陆续地研究了AQS的底层原理,同时研究了AQS在不同场景下的三个应用工具类(ReentrantLock、CountDownLatch、Semaphore)的工作原理,之所以和大家一起分析它们,是因为这三个类是我们平时工作中应用最多的类了,其实在J.U.C中,还有好多直接或者间接通过AQS实现的工具类,比如读写锁ReentrantReadWriteLock、循环栅栏CyclicBarrier等。
本篇我们将一起对AQS的另一类的应用场景的实现类——阻塞队列(实现生产者/消费者模型的经典方法) 做一次深入浅出的分析。
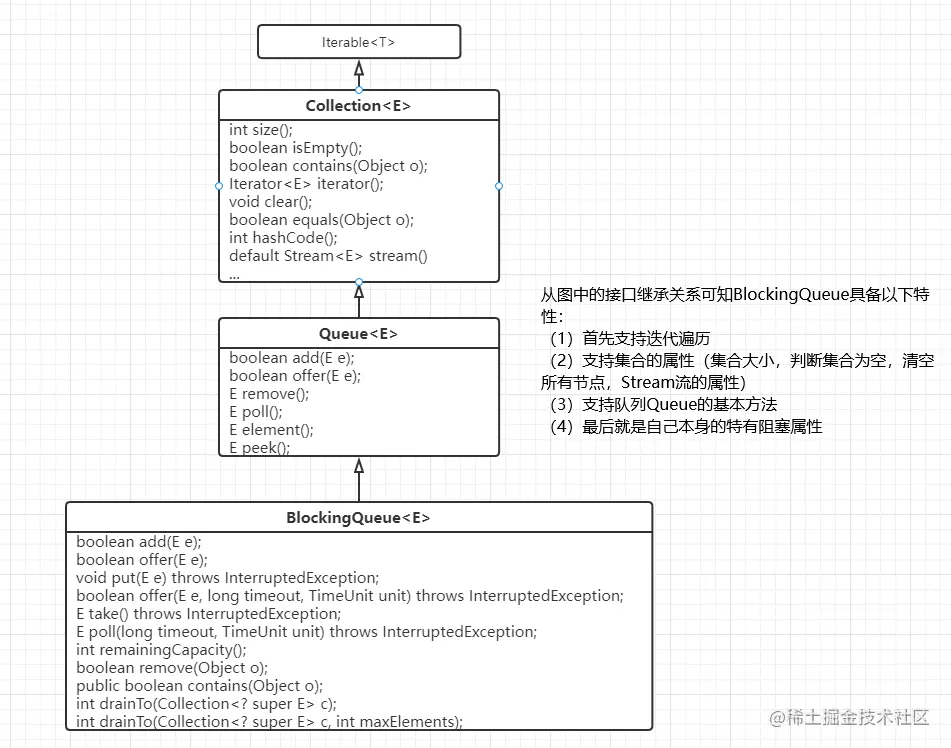
从上面的类图结构和源码的注释分析来看,我总结如下:
从上面总结的第一和第二点我们知道,BlockingQueue的接口方法包含四种类型的:会抛异常的、返回特殊值的、会阻塞的和阻塞有超时的;但是按照操作结果大体可分为三种(官方区分的):插入型的、删除型的、读取型的。如下面的表格总结(其实也是源码的注释内容):
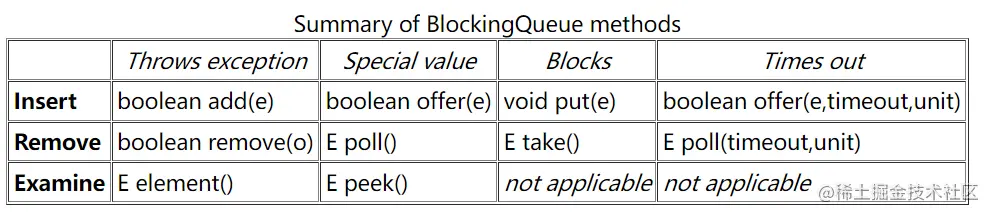
下面我们就此表格说明下(我又多分了一个种类->读取删除型,这样更清晰些):
直接上图:
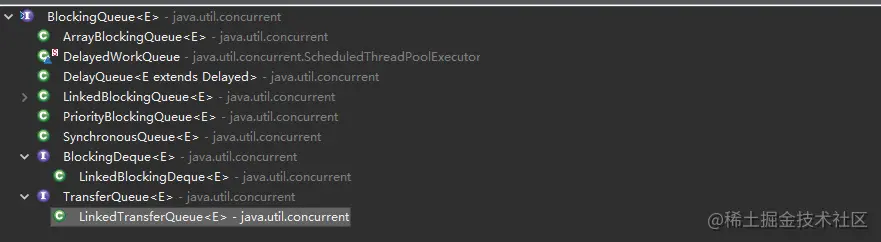
从图中可以知道:
ArrayBlockingQueue是一个通过数组实现的有界阻塞队列。通过FIFO先进先出的方式操作元素,即队头的元素在队列中停留的时间最长,队尾则最短。新元素以尾插入的形式入队,读取将从队头开始。
ArrayBlockingQueue可以作为一个“有界缓冲区”,是实现生产者/消费者场景的重要手段。生产者生产元素放入队列,消费者从队列读取进行消费。队列满的时候,生产者就不能继续往里面放入元素,则必须阻塞等待;同样的,当队列为空时,消费者就取不到元素而阻塞等待。ArrayBlockingQueue一旦在创建时初始化了容量大小,就不会变化了(如果随时扩容/减少怎么可以阻塞等待呢)。
同时,ArrayBlockingQueue可以支持生产消费过程的是否公平。默认情况是非公平的,当然你也可以自己设置。至于公平和非公平的优缺点这里就不叙述了,看这里。
LinkedBlockingQueue从名字就可以看出,它是一个以链表形式实现的队列,它同样是个有界阻塞队列,可以在初始化的时候指定大小,如果不指定,则默认为Integer.MAX_VALUE。相比较ArrayBlockingQueue而言,LinkedBlockingQueue的吞吐量表现更好点,除了这个其他特性几乎和ArrayBlockingQueue差不多。
BlockingDeque继承于BlockingQueue,是一个阻塞有界双端队列,即队列的头和尾都可以进行插入,删除,读取操作。同样的,我贴出官方的表格:(细节就不再叙述,其实都差不多,从方法名字也可以看出来是干嘛的了)
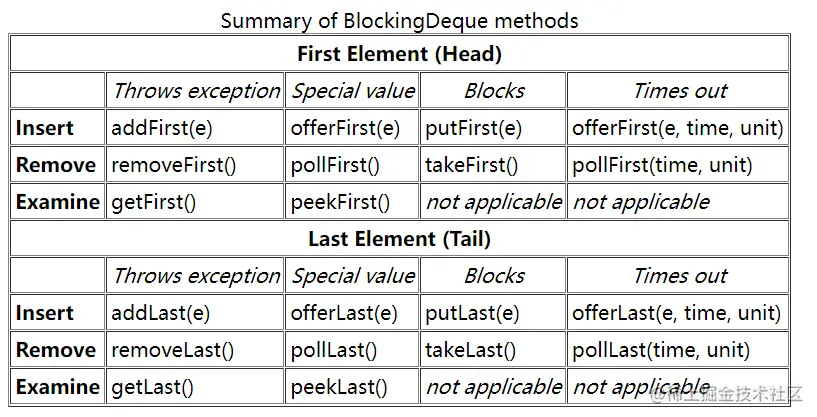
和BlockingQueue的主要区别就在于,BlockingDeque是两头都可以操作。
LinkedBlockingDeque就是对BlockingDeque的具体实现,基于链表形式的实现。其具体实现的理念和LinkedBlockingQueue也差不多,也不再叙述了。
PriorityBlockingQueue从名字来看,是一个跟优先级有关系的阻塞队列,准确的说,它是一个支持优先级的无界阻塞队列,其内部定义了Comparator属性,我们可以通过这个自定义元素的排列顺序而改变出队的顺序,从而实现优先级,观其构造器就可知一二:
public PriorityBlockingQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
this.comparator = comparator;
this.queue = new Object[initialCapacity];
}
由于是无界,所以使用时小心资源耗尽,发生OOM。
Synchronous从英文翻译来看很有意思,同步的队列。乍一看,不懂。。。。源码注释里写道:这是一个阻塞队列,它的每个插入操作必须等待另一个线程执行相应的删除操作,反之亦然。你无法查看同步队列,因为只有当你试图删除一个元素时,它才会出现;你不能插入一个元素(使用任何方法),除非另一个线程试图删除它;你不能迭代,因为没有东西可以迭代。队列的头部是第一个插入队列的线程试图添加到队列中的元素;如果没有这样的队列线程,那么就没有可以删除的元素,poll()将返回null。
感觉有点绕,简单来说,该队列无法对元素数据进行存储,无法查看队列里的情况,也无法进行元素数据的迭代,原因就是,一个线程插入完成,就会被另一个线程取走;一个线程取走了,又会再有一个线程继续插入。顾名思义,其实这个队列的数据,感觉像是同步的,插入了就会被取走,取走后就会被再次再次插入。(除非是非常非常巧合的情况下说不定会查看到队列的元素数据)
TransferQueue除了继承了BlockingQueue的方法之外,还补充了符合该类特性的方法->Transfer:转移传输的意思,具体哪些呢?如下图接口定义:
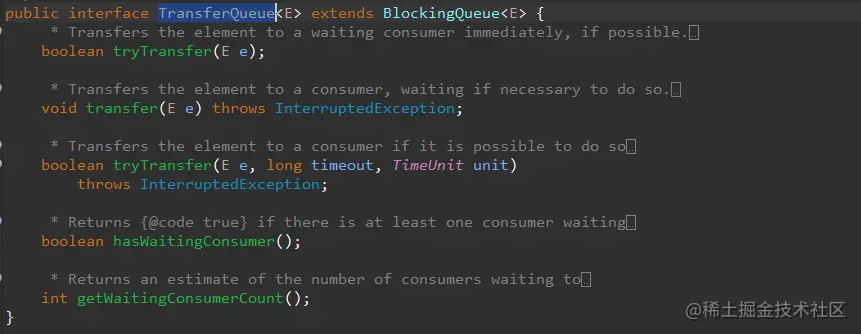
从源码贴图可知,主要多了上面几个方法:
LinkedTransferQueue就是TransferQueue的具体实现,是基于链表形式的无界传输阻塞队列,符合FIFO特性,除了以上介绍的transfer特殊属性外,其他特性和其他实现类差不多。
DelayQueue:一个用来存放延迟元素的无界阻塞队列,这个队列不知道大家有没有使用过,它是实现延迟队列的重要手段之一。 其里面维护的元素数据是一个实现Delayed接口的自定义实现类的对象,这个类会实现一个方法【long getDelay(TimeUnit unit)】,如果该方法返回一个小于或等于0的值,就表示里面的元素已经到达设定的延迟时间,这时就会把元素放入到队列当中。具体原理我会在后面专门写一篇文章来阐述。
阻塞队列BlockingQueue及其所有实现类的简单介绍到此结束,下面我们将从上面的具体实现类选取ArrayBlockingQueue作为本篇的另一个主角,来看看具体的阻塞队列是如何实现的。
(PS:很重要的一点,注意每个队列的名字,有界和无界,使用无界队列的时候一定要小心OOM)
从上面分析阻塞队列以及ArrayBlockingQueue的简单介绍来看,ArrayBlockingQueue最重要的功能就是,能够在操作元素(插入和读取删除)的时候阻塞。其工作原理就是,当ArrayBlockingQueue队列为空时,会阻塞消费者读取数据,直到队列有数据时唤醒消费者继续;当队列满的时候,会阻塞生产者进行插入数据,直到队列有剩余空间时,会唤醒生产者继续插入。
在之前的篇章中,我们就已经知道,wait/notify是实现生产者/消费者的重要手段之一,是通过线程间的通信来完成的,那在我们J.U.C包里,会不会是通过Condition的等待队列机制实现的呢?我们一起来看下,上源码:
/** The queued items */
final Object[] items;
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
从这段代码其实我们就已经知道了上面问题的答案,确实是通过Condition的等待队列机制实现的。
我们再来看看构造器,一共重载实现了三个构造器,如下:
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
this(capacity, fair);
final ReentrantLock lock = this.lock;
lock.lock(); // Lock only for visibility, not mutual exclusion
try {
int i = 0;
try {
for (E e : c) {
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
count = i;
putIndex = (i == capacity) ? 0 : i;
} finally {
lock.unlock();
}
}
从构造器可以看出,ArrayBlockingQueue公平/非公平都支持,默认使用非公平模式。初始化的时候,就已经将消费/生产两大条件等待队列初始化完成了。
public void put(E e) throws InterruptedException {
checkNotNull(e);
/**
为了保证操作的原子性,上来先上锁
*/
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
/**
当前队列元素实际个数count如果等于数组定义的大小的话,则说明队列里已经满了
则会调用生产者等待队列的阻塞await方法,对当前消费者线程进行阻塞
注意:这边是个while循环,跳出循环的唯一条件就是,count!=items.length,什么情况才会
不相等呢?当然是队列中的元素被读取删除的时候
*/
while (count == items.length)
notFull.await();
/**
如果不满足上面的条件或者生产者被唤醒从阻塞状态回归时,将调用enqueue(e)方法进行入队操作。
*/
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
/**
这部分的代码就很简单了
首先,就是将当前需要入队的元素,放入putIndex下标对应的坑中
其次,将putIndex执行+1操作,如果+1后等于数组的长度,说明下标走到尽头了,得重新开始,于是执行=0操作
最后,以上操作都成功的话,将元素个数count执行+1;并且调用消费者等待队列,唤醒一个阻塞的消费者进行
消费
*/
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
流程比较简单,看代码注释即可明白啦~~
public E take() throws InterruptedException {
/**
同样的,进入方法先上锁,保证原子性操作,其实也不仅仅是为了保证原子性
我们在之前讲过Condition的原理的时候说过,调用其方法前必须先lock
*/
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
/**
几乎和上面一样,首先是个while循环,条件是当前元素的个数是否为0
如果为0,说明队列里没数据可以读取消费,则执行notEmpty.await()对消费者阻塞
如果不为0或者从阻塞等待队列中被唤醒,则执行出队操作dequeue()
*/
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
/**
首先,取出当前takeIndex下标对应的元素,并且置为空
其次,takeIndex执行+1操作,并判断是否等于数组大小,判断和上面一样哈~
最后,count进行-1操作,因为出去了一个元素;并且调用生产者继续放入元素
*/
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
同样的,代码注释里,已经分析清楚了~~至于其他的一些操作方法小伙伴们可以自己去看哈~也比较简单。
到此,我们想要了解的都理清楚了,简单总结下:
有了之前AQS的基础,理解阻塞队列ArrayBlockingQueue的原理是不是轻松加愉快呢~当然我们后面也会选一些其他的实现类来分析的,有的可能就比ArrayBlockingQueue复杂多了。
下面我们写个简单的示例,来加深下对阻塞队列ArrayBlockingQueue的理解。
场景描述:一个队列大小为5的阻塞队列,多个生产者往队列放入随机号,一个消费者进行读取消费。
public class ArrayBlockingQueueDemo {
public static void main(String[] args) {
ArrayBlockingQueue queue = new ArrayBlockingQueue<>(5, true);
//先把消费者搞起来
Thread consumer = new Thread(new Runnable() {
@Override
public void run() {
try {
for (;;) {
String value = queue.take();
System.out.println("消费者取出了值" + value);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "consumer");
consumer.start();
//循环启动10个生产者
for (int i = 0; i < 10; i++) {
Thread producer = new Thread(new Runnable() {
@Override
public void run() {
try {
String value = UUID.randomUUID().toString();
System.out.println(Thread.currentThread().getName() + "放入值:" + value);
queue.put(value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "producer" + i);
producer.start();
}
}
}
/*运行效果
producer1放入值:e06ee09f-46c0-4c33-92b3-53b4300fc1af
producer5放入值:03ed5819-6b51-4ef9-bb93-5f048ead0a1e
producer4放入值:9988b80b-7218-4b95-bbe0-e6d8ec00ba38
消费者取出了值e06ee09f-46c0-4c33-92b3-53b4300fc1af
producer3放入值:01fc2d1c-6fc5-4968-b5ef-dde07639bde4
producer8放入值:410903e5-4e4d-4310-a84d-b87f94f4a797
producer0放入值:3323dda4-baf4-4b27-b574-95cda9ce0b14
producer7放入值:13fc6650-69ff-433e-bdd3-4e726d41abdf
producer2放入值:e398813a-8b50-4221-8a13-845ae91a453a
producer6放入值:9696211c-f2bf-466a-bebc-b55de4608108
producer9放入值:f106cffa-351e-4d4e-ad1a-6986f7136c3a
消费者取出了值03ed5819-6b51-4ef9-bb93-5f048ead0a1e
消费者取出了值9988b80b-7218-4b95-bbe0-e6d8ec00ba38
消费者取出了值01fc2d1c-6fc5-4968-b5ef-dde07639bde4
消费者取出了值410903e5-4e4d-4310-a84d-b87f94f4a797
消费者取出了值3323dda4-baf4-4b27-b574-95cda9ce0b14
消费者取出了值13fc6650-69ff-433e-bdd3-4e726d41abdf
消费者取出了值e398813a-8b50-4221-8a13-845ae91a453a
消费者取出了值9696211c-f2bf-466a-bebc-b55de4608108
消费者取出了值f106cffa-351e-4d4e-ad1a-6986f7136c3a
当然效果每次运行都会不一样的,你可能会有疑问,不是生产一个消费一个吗?
你错了,我们模拟的是多个生产者,只有一个消费者,当消费者在消费打印的时候,说不定已经生产好几个了。
请注意,这是一个高并发场景。
*/
由此我们看出,只有生产者生产放入数据后,消费者才会进行读取消费。
到此,本篇到此结束啦~你学会了吗?~~
作者:会飞的鱼2022
链接:https://juejin.cn/post/7117889476709318669
| 留言与评论(共有 0 条评论) “” |














